Understanding and Addressing Obesity: A Data-Driven Approach
Introduction
Obesity is a growing global concern with significant health implications. By leveraging advanced machine learning models, our project aims to understand and address the impacts of obesity on the population. This blog delves into how we use data and technology to comprehend and predict obesity trends and integrate these insights into practical health initiatives.
Data Collection
Our project utilizes a diverse dataset collected from Mexico, Peru, and Colombia. This dataset includes 17 attributes that encompass various aspects of eating habits, physical activity, and other lifestyle factors. Attributes such as gender, age, height, weight, family history of obesity, consumption habits, and physical activity levels provide a comprehensive view of the factors influencing obesity.
Data Preprocessing
Before diving into model building, we meticulously preprocess the data to ensure quality and accuracy. Key steps include:
- Removing Duplicate Rows: Eliminating duplicate entries to prevent distortion in analysis.
- Converting Categorical Values: Smoothing regression modeling by converting non-integer values into integers.
- Handling Missing Values: Removing rows with missing data points to maintain consistency.
Model Selection and Experimentation
To uncover meaningful insights, we experimented with several machine learning models:
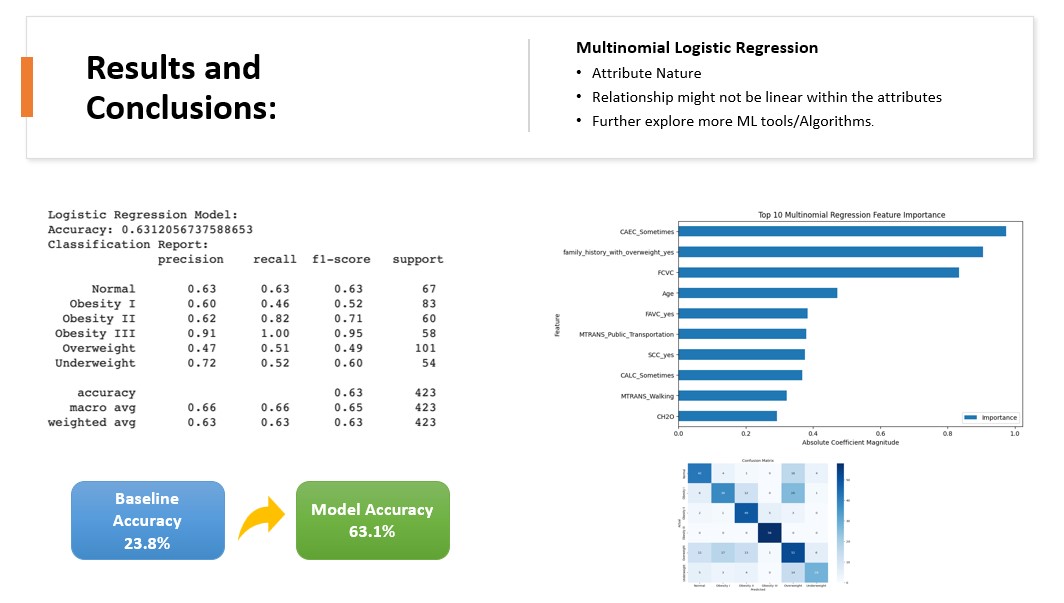
- Multinomial Logistic Regression: Chosen for its flexibility in handling non-linear relationships and categorical outcomes.
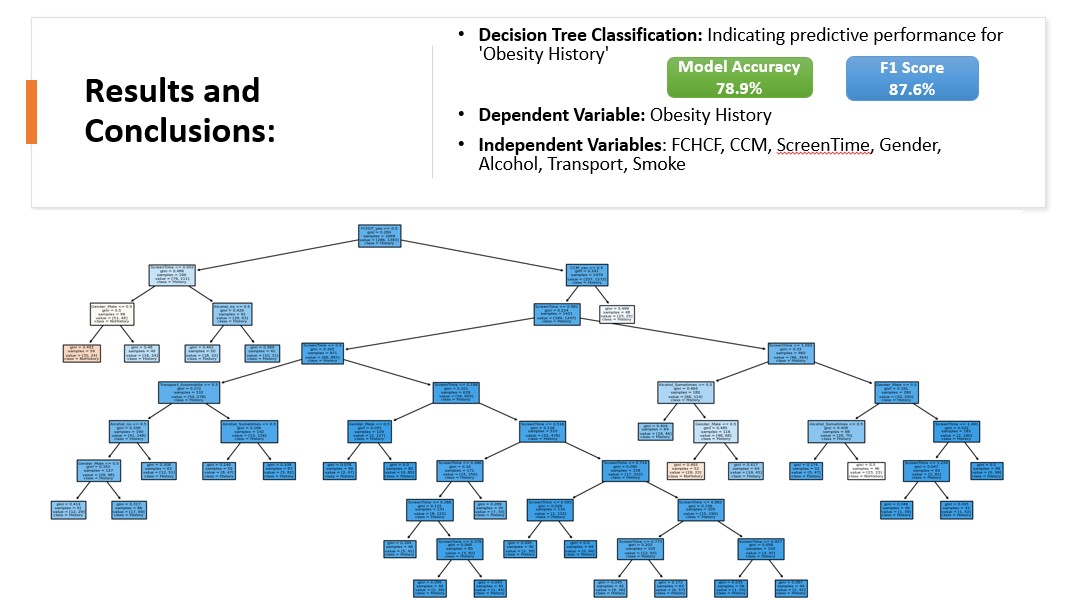
- Decision Tree Classification: Used to predict obesity categories based on selected features, providing interpretability and insights into feature importance.
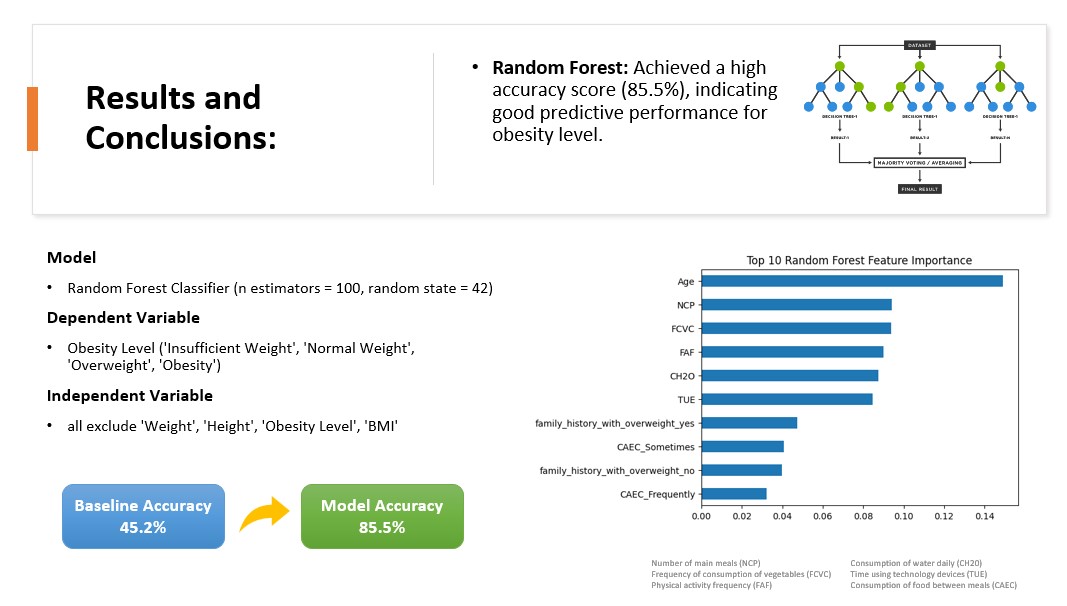
- Random Forest: Applied to examine nonlinearity and enhance predictive outcomes.
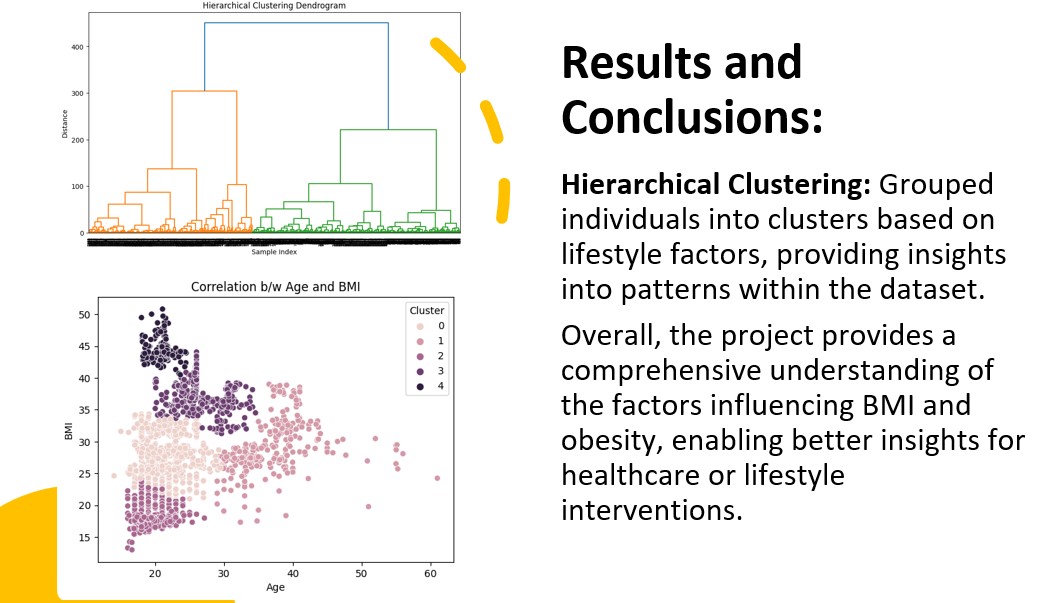
- Hierarchical Clustering: Utilized to explore lifestyle patterns and identify groups with similar characteristics.
Technical Findings
- Random Forest: Achieved the highest accuracy (85.5%) for predicting obesity levels.
- Multinomial Logistic Regression: Showed a model accuracy of 63.1%.
- Decision Tree Classification: Achieved a model accuracy of 78.9% with an F1 score of 87.6%.
- Hierarchical Clustering: Identified distinct lifestyle patterns, aiding in targeted interventions.
Challenges and Enhancements
Throughout the project, we encountered several challenges, primarily related to data quality:
- Duplicate Rows: Addressed by removing duplicates.
- Categorical Values: Converted non-integer values for smoother regression modeling.
- Missing Values: Eliminated rows with missing data to ensure consistency.
By tackling these challenges head-on, we enhanced the overall model performance, ensuring the insights derived are robust and reliable.
Implications and Applications
The ultimate goal of our project is to integrate the insights derived from these models into practical health initiatives. These include:
- Policy Formulation: Using model insights to inform and shape health policies.
- Resource Allocation: Guiding the distribution of resources based on predictive analytics.
- Intervention Design: Tailoring interventions based on model outcomes to address specific patterns in nutritional habits and physical activity levels.
- Preventive Programs: Launching educational campaigns and community fitness initiatives informed by trend predictions.
- Monitoring and Evaluation: Utilizing models for ongoing assessment and adjustment of health strategies.
Conclusion
By leveraging machine learning models and comprehensive data analysis, we aim to enable a deeper understanding of obesity prevalence and incidence. This data-driven approach facilitates the creation of effective and targeted health strategies, ultimately contributing to a healthier society.